Trong bối cảnh bùng nổ dữ liệu như hiện nay, việc xử lý và phân tích lượng thông tin khổng lồ đã trở thành một thách thức cốt lõi đối với các tổ chức. Từ những ngày đầu của “Big Data”, các công nghệ đã liên tục phát triển để đáp ứng nhu cầu ngày càng cao về tốc độ, hiệu quả và khả năng xử lý dữ liệu theo thời gian thực.
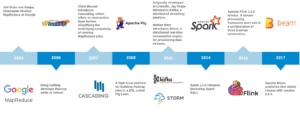
Trước khi đi vào nội dung chính, chúng ta sẽ cùng nhìn lại hành trình tiến hóa của các giải pháp xử lý dữ liệu lớn. Khởi đầu với MapReduce, một mô hình lập trình và công cụ xử lý phân tán ra đời từ Google, cho phép các tác vụ xử lý dữ liệu lớn được chia nhỏ và thực hiện song song trên nhiều máy tính. MapReduce, với ưu điểm về khả năng mở rộng và chịu lỗi, đã trở thành nền tảng cho Apache Hadoop, một hệ sinh thái mạnh mẽ cung cấp không chỉ khả năng xử lý mà còn cả hệ thống lưu trữ phân tán (HDFS). Tuy nhiên, MapReduce chủ yếu tập trung vào xử lý theo lô (batch processing), tức là xử lý toàn bộ dữ liệu sau khi đã thu thập xong, điều này thường dẫn đến độ trễ cao và không phù hợp với các ứng dụng yêu cầu phân tích tức thì.
Để khắc phục hạn chế này, Apache Spark đã xuất hiện như một thế hệ tiếp theo trong xử lý dữ liệu, tập trung vào tốc độ và tính linh hoạt. Spark mang đến khả năng xử lý dữ liệu trong bộ nhớ (in-memory processing), nhanh hơn đáng kể so với MapReduce vốn phải đọc hoặc ghi dữ liệu liên tục lên ổ cứng. Spark không chỉ hỗ trợ xử lý theo lô mà còn tích hợp các module cho xử lý luồng (Spark Streaming), xử lý đồ thị (GraphX) và học máy (MLlib), mở ra nhiều ứng dụng mới. Tuy nhiên, Spark Streaming hoạt động theo cơ chế micro-batching, tức là gom dữ liệu thành các lô nhỏ trước khi xử lý. Dù độ trễ đã giảm đáng kể so với MapReduce, nhưng vẫn chưa đạt mức “gần thời gian thực” (near real-time) thực sự.
Để đáp ứng nhu cầu xử lý dữ liệu theo thời gian thực một cách thực sự, Apache Flink đã được phát triển như một bước tiến tiếp theo trong lĩnh vực xử lý dữ liệu lớn. Nếu như Apache Spark mở rộng khả năng xử lý theo lô với tốc độ vượt trội nhờ cơ chế xử lý trong bộ nhớ (in-memory computing), thì Flink lại tập trung vào xử lý luồng thực sự (true stream processing), nơi mỗi sự kiện (event) được xử lý ngay tại thời điểm nó xảy ra, thay vì phải gom thành các lô nhỏ như trong Spark Streaming.
Flink được thiết kế với độ trễ cực thấp, có khả năng duy trì trạng thái của các sự kiện (stateful computations), và hỗ trợ tốt cho cả luồng unbounded lẫn bounded, giúp xử lý linh hoạt trong cả môi trường streaming lẫn theo batch. Theo trang chủ của Flink, dưới đây là dòng giới thiệu về Flink:
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Những nội dung mình chia sẻ trong blog chỉ mang tính chia sẻ cá nhân. Nếu các bạn có bất kỳ thắc mắc nào, hãy để lại bình luận dưới bài viết – mình sẽ cố gắng phản hồi trong khả năng của mình.
Trong chuỗi bài viết về Apache Flink, mình sẽ đi từ những khái niệm cốt lõi đến cách triển khai thực tế. Dưới đây là các chủ đề chúng ta sẽ cùng khám phá:
Bài 1: Giới thiệu Apache Flink
- Flink dùng để làm gì?
- So sánh với Spark, Kafka Streams
- Kiến trúc tổng quan của Flink (JobManager, TaskManager)
- Ưu điểm chính: Stateful, Event-time, High Throughput

